QCon London 2017 takeaway points



here is the schedule: https://qconlondon.com/london-2017/schedule/tabular
so what was it all about?
- key topic: performance
- keywords: serverless, automation, scaling, iot, containers, git, devops, ci, mobile, javascript
- more keywords: drive change, innovation, diversity and equality in the workplace
- waterfall is absolutely dead: agile/scrum is what it is since 2008. since 2012 it's about scaling agile and scrum.
- soap is absolutely dead. nobody even mentioned it. rest/swagger is what it is.
day 1
Security War Stories: The Battle For The Internet of Things
security is important, iot things are not secure, i can change your radio station and view your webcams, blablayaddayadda
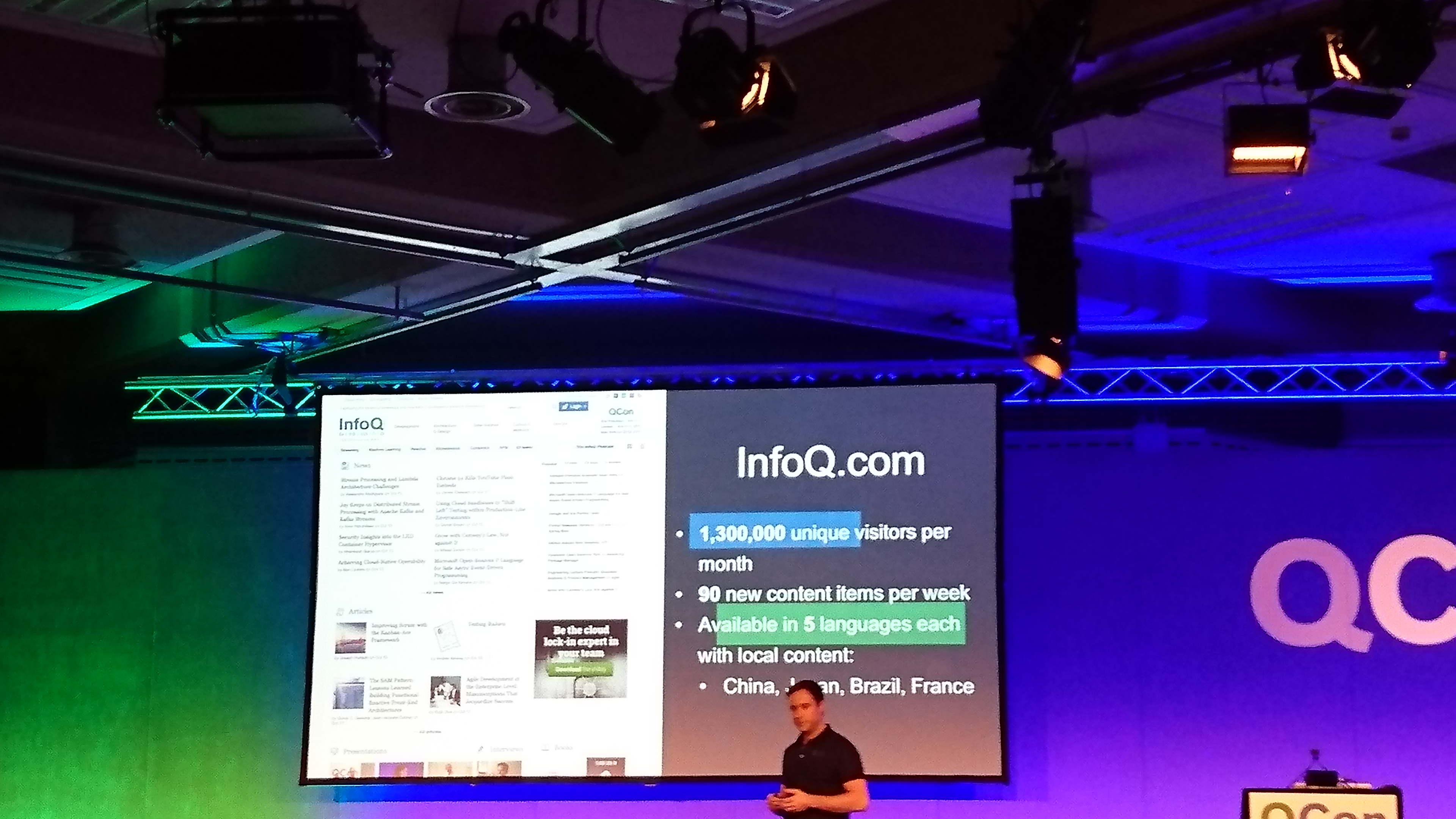
Microservices At The Heart of BBC iPlayer

they had a big monolythic java app that did not meet demand.
so they had to do something: refactor the app to a lot of little apps.
had to pre-warm the caches before even putting the service online.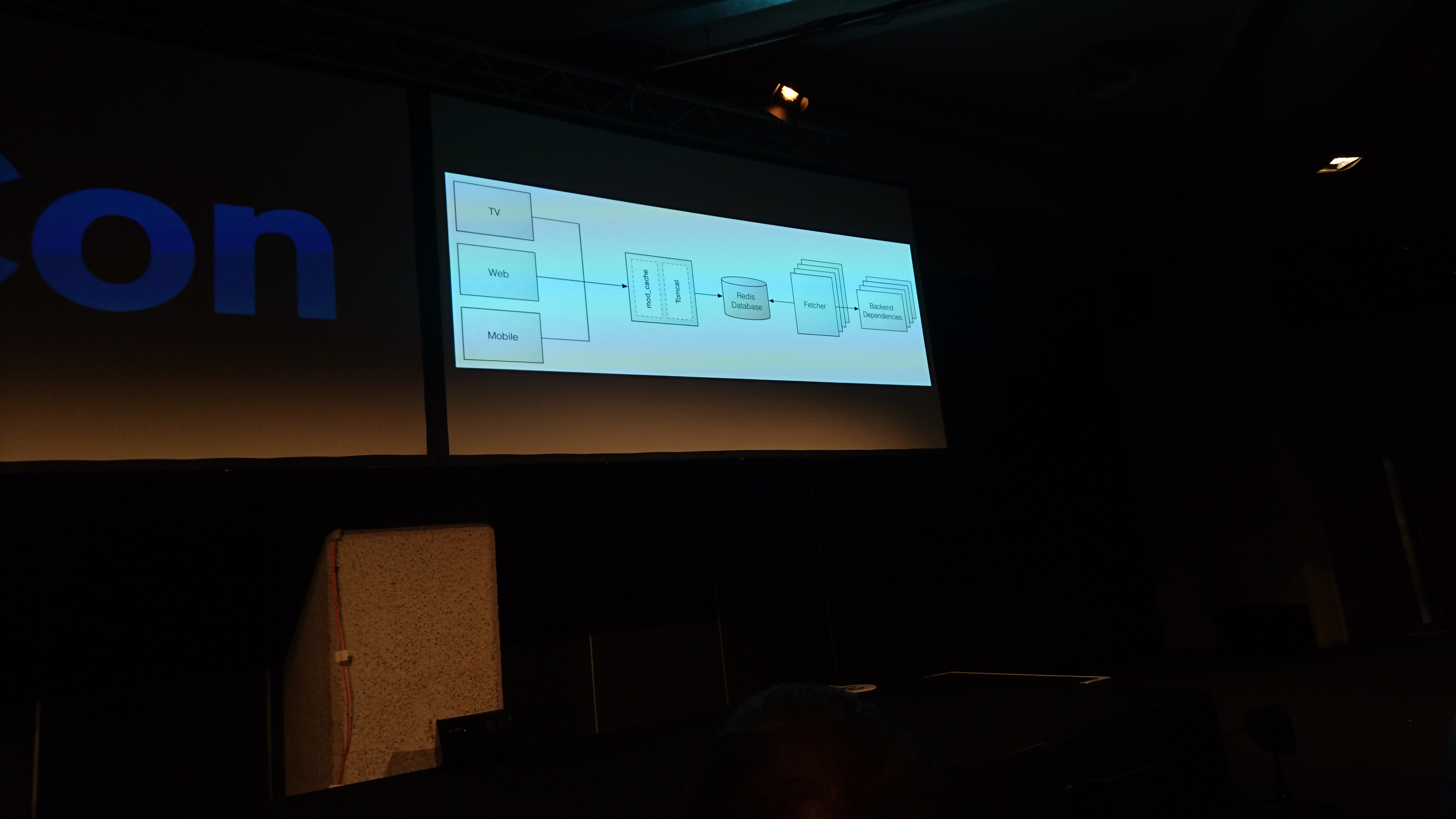
step by step re-architecturing the app.
reasons to choose node:
- it's fast
- they already knew js
response times before where 5seconds, with node 10ms - 100ms now is slow.
parts of the app are now
- independently deployable
- independently scalable
- independently failable
(almost)
team workflow is now better: everyone can focus just on the piece that concerns them.
tdd development with pairing. there is a test for almost everything, and everyone has a backup. no one person owns a service anymore. the team owns all of the services.
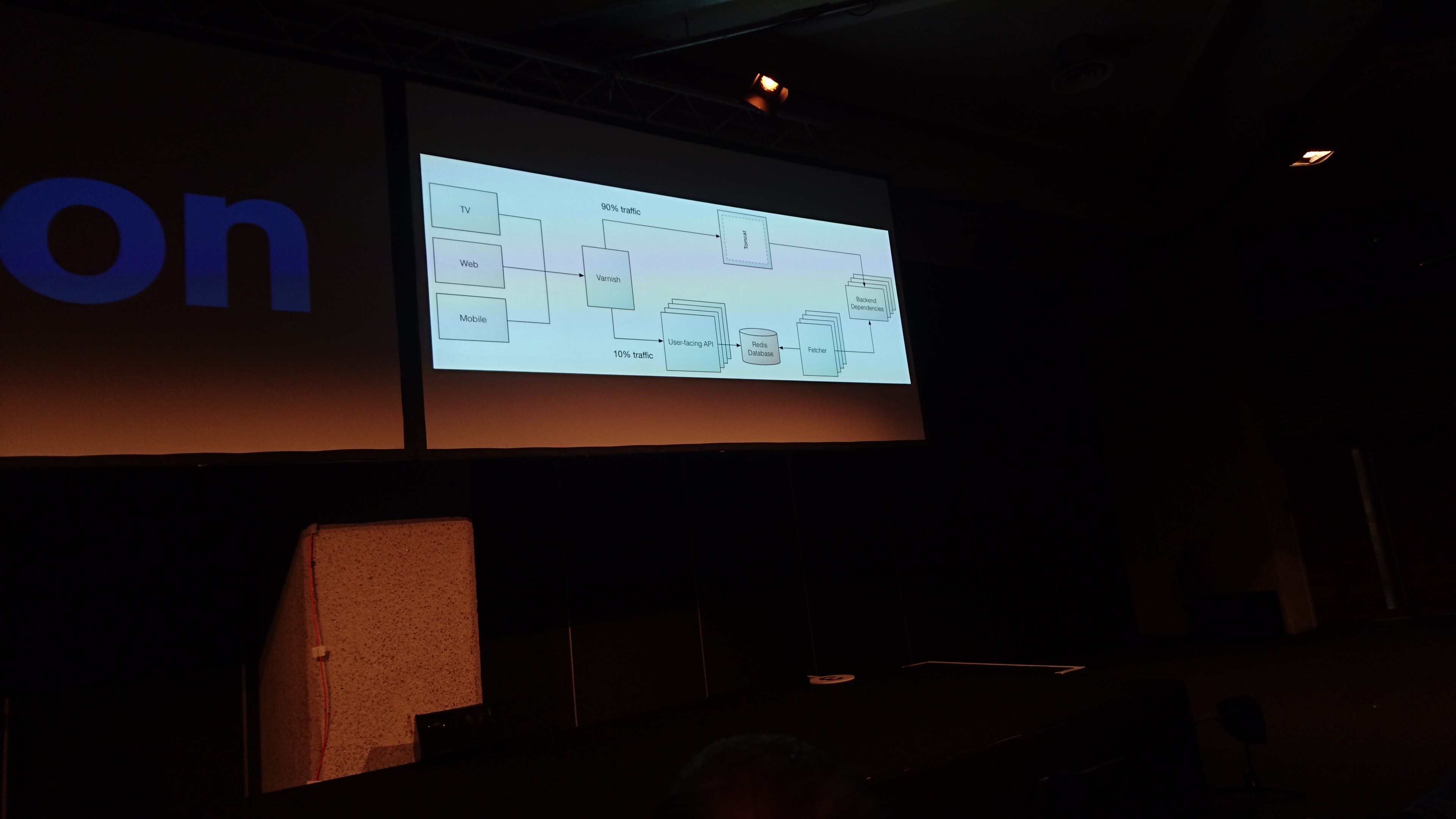
problems faced: redis was a central point of everything, so there was no confidence in changing something that involved redis. solution: abstract redis with an api, and use multiple redis databases, one for episodes, one for shared stuff, ...
use yeoman to automate the creation of the small apps. this reduced the ammount of configuration essentially to 0.
seyren to check/monitor services.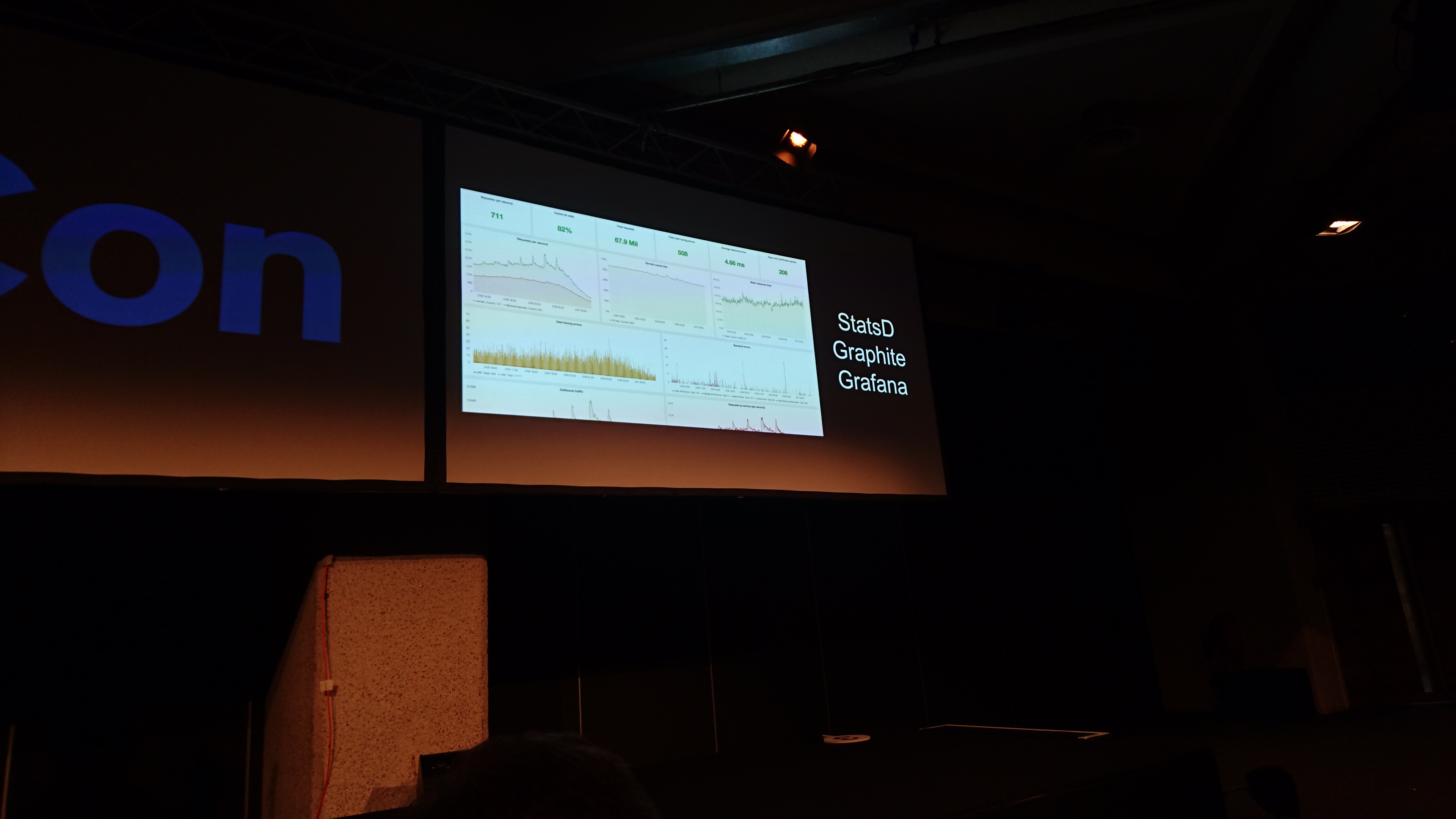
everything over https and keep-alive internally.
deleting the shared database: we checked if something writes or reads from it. but there was some obscure software that was reading and writing to it every 40 minutes... deplyed a fix for it.
every piece of software now has it's own db, and is autonomous.
everything is consistent with node and js on the frontend. no context switching.
the team is just 4 people, with no pm.
consumer contracts help a lot with independence between client and api services.
moving from redis to postgres for some service because the requirements become more complex. redis is just a store, postgres can have complex sql reports.
The Hitchhiker's Guide to Serverless Javascript

we are not talking about servers anymore, but about platforms.


the talk is mainly about amazon aws.
api gateway is routing as a service. this is what makes serverless ultimately possible.
swagger or "click around a lot".
so the architecture is more or less html + js -> api gateway -> lamda
would be nice to have in our infra!
why serverless?
- ops:
#noops - #lessops
- benchmarks
- fallbacks
- load testing
- monitornig
- scaling: up AND down
- single function deployments
vendor lockin? yes, it is a problem. serverless framework tries to abstract that away, hopfully we will get there.
granularity on functions as a service compared to microservices: you can do microservices with faas.
Enabling Innovation at Uber Speed

innovation is really important for uber, the team has to enable it.



workation
you go there, and work on your idea for a week/10 days, and then you come back.
"find the perfect match both in terms of skill and cultural fit"
...
we hire great people, and we need to empower them and keep them motivated, and blabla...
it's ok to fail. postmortems are really important because we want to understand what went wrong.
Continuous Performance Testing


once upon a time, when there was a new release, on the lunch break everybody logged on and tested the app.
now we use tools to do it, and run it as part of jenkins or our ci.
keep the numbers, so we see how the speed changes over time. if there are regressions we can handle them.
different types of benchmarks and when they make sense:


Async or Bust!?



so async or sync? all we want is the simplicity of sync to reason about the code, but the efficiency of asncronicity: do something while we wait.
talk goes on on how to handle async code, but in the end async is just a different paradigm:
- callbacks,
async, ... - handle errors like events

Rebuilding The Monolith With Composable Apps

skybet had a php app that was really convulted and made of bad code, but it worked and was used a lot.

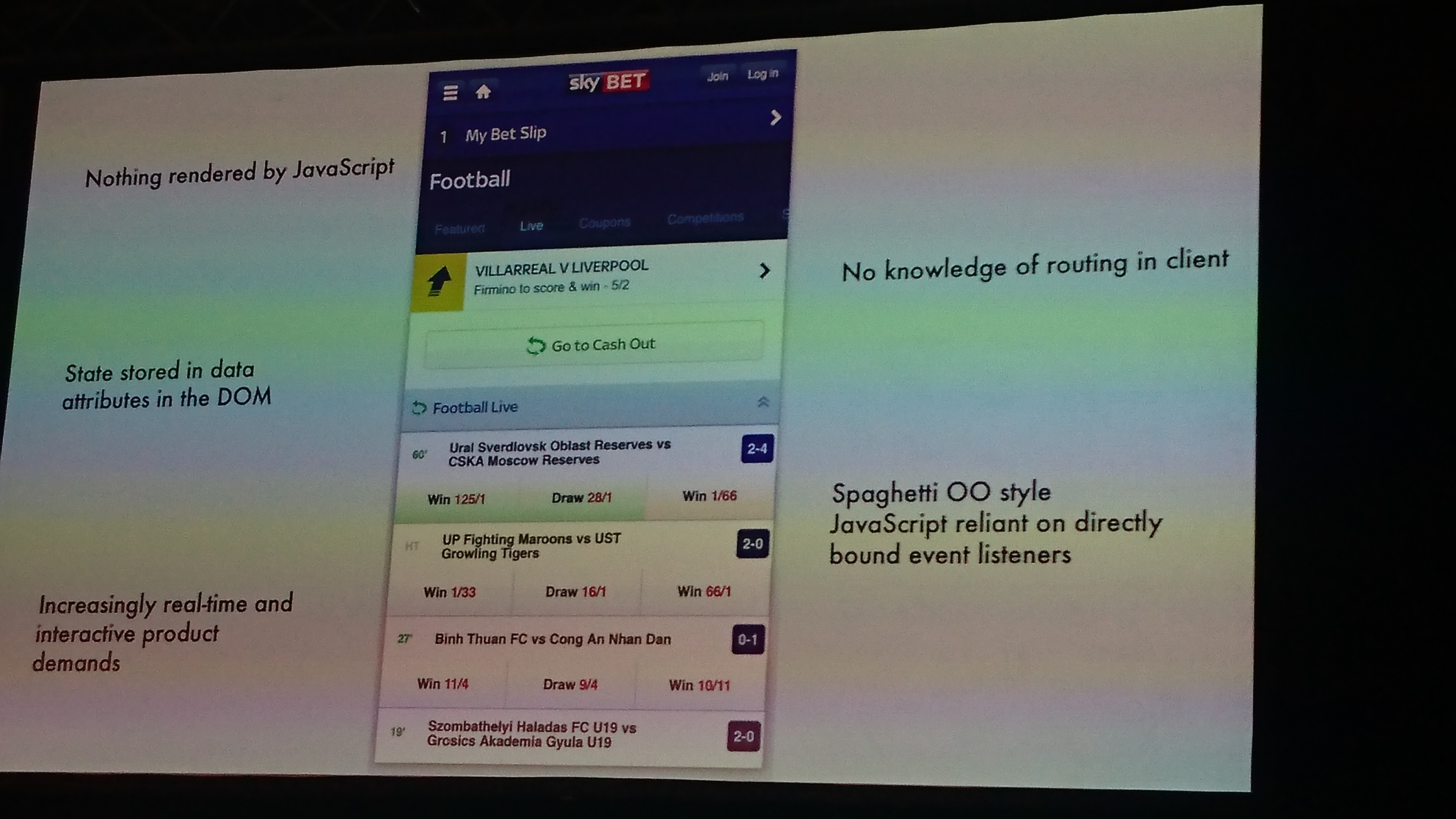
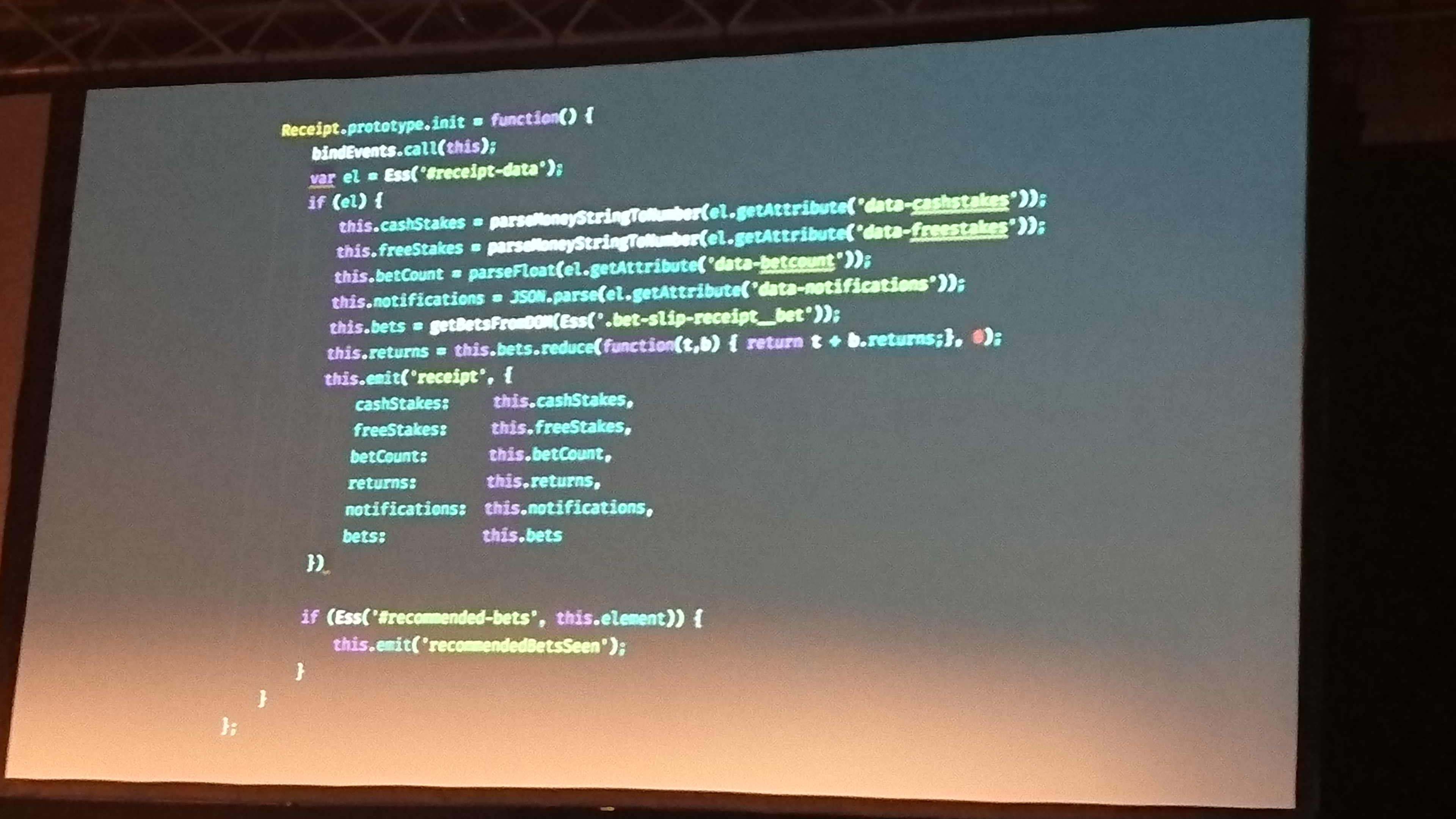

they needed to implement some things that could not be done with the old architecture (live updates, be fast, ...), so they choose a new architecture based on the same old js -> api -> db, and started to refactor pieces of the old app, until most of the old app was made using the new tech (openkat!).

with react they could partially do that.
day 2
Engineering You
QCon tries to make you stay one step ahead of the adoption curve.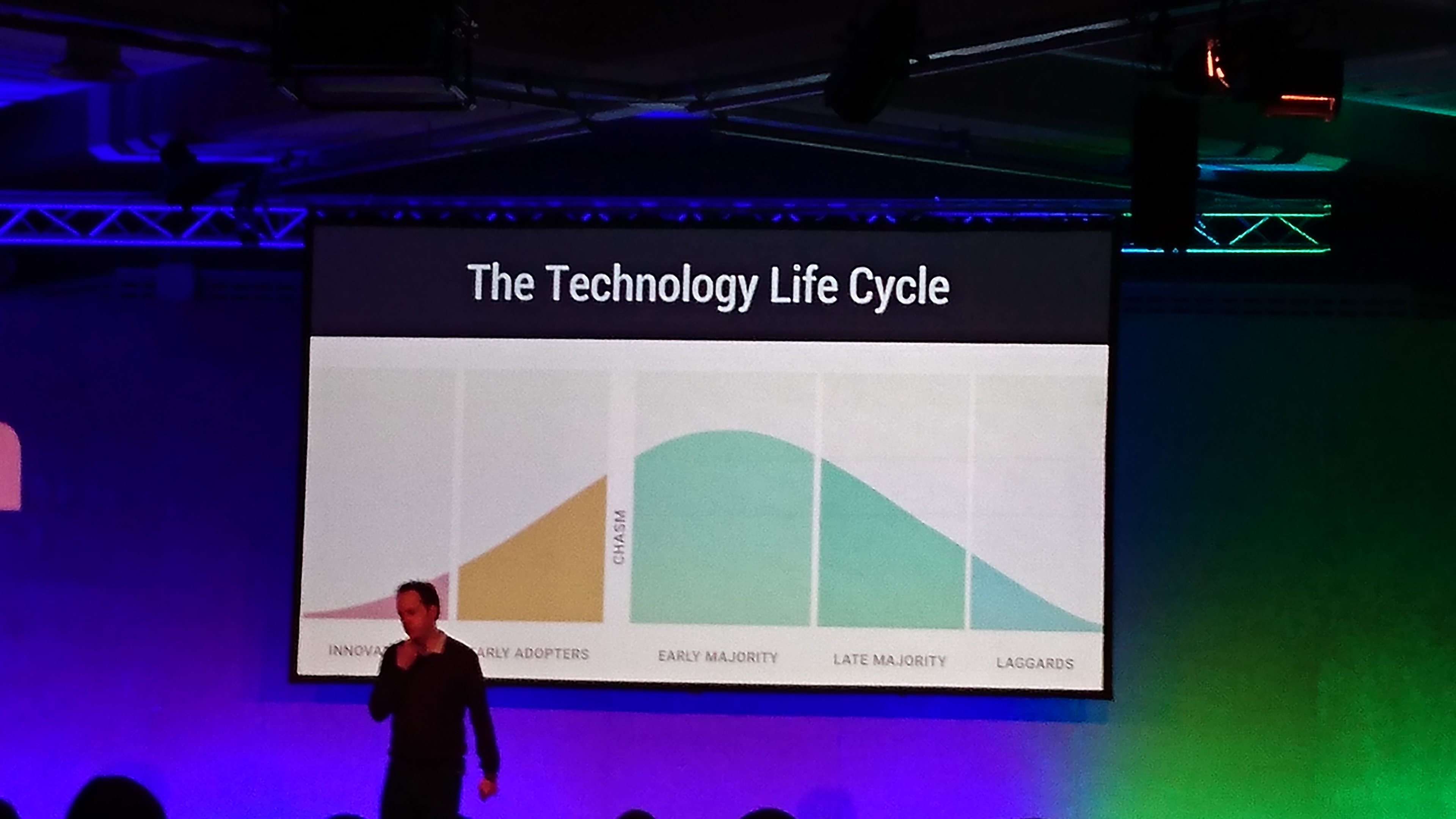

Keynote: we need to be more inclusive in our industry.
Architectural Overhaul: Ad Serving @Spotify Scale


the ad serving at spotify is a powerful messaging platform:
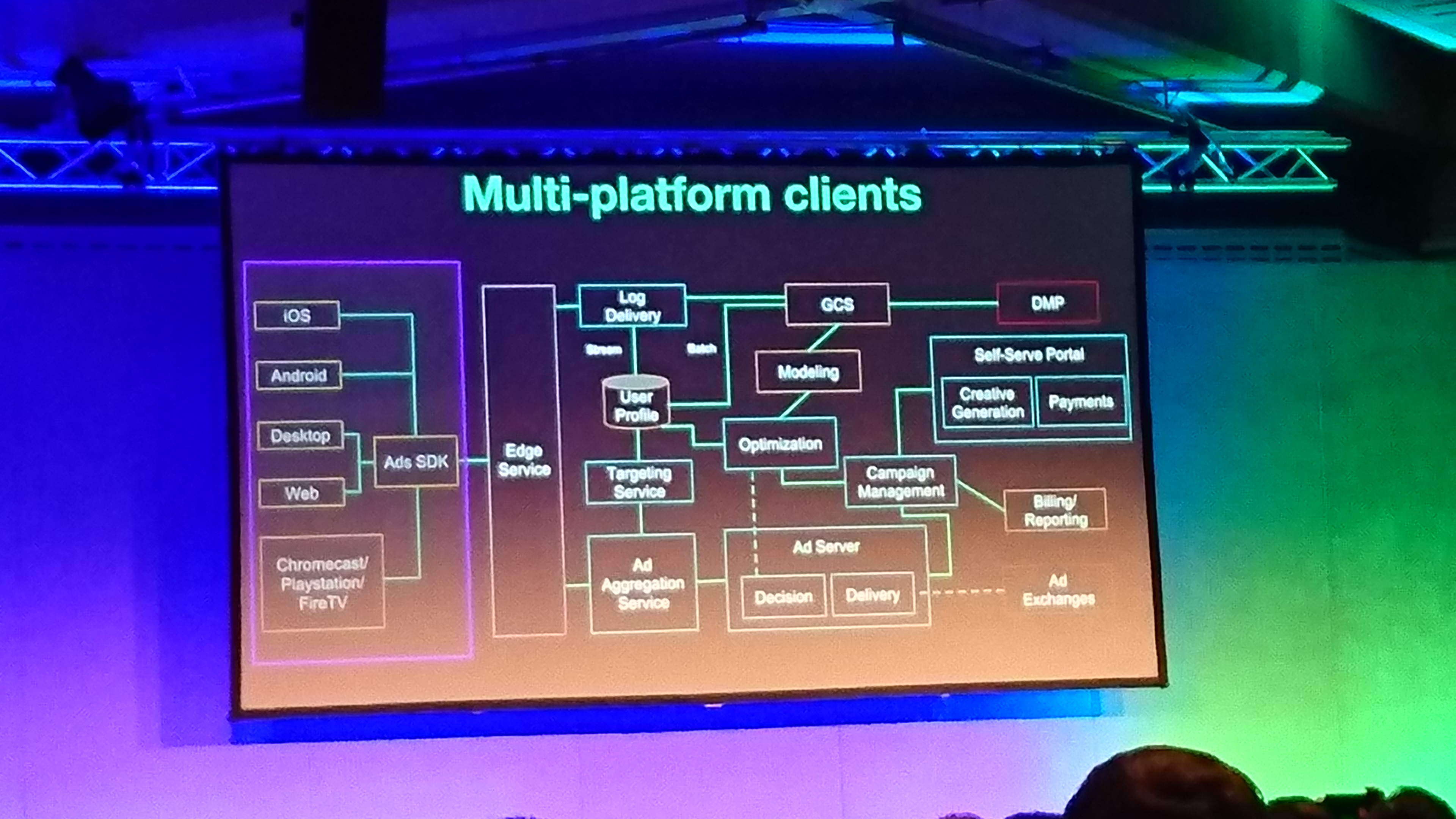

two main parts: the client and the ad server.
the ad server had to be refactored because
- it had logic in the client
- did not scale
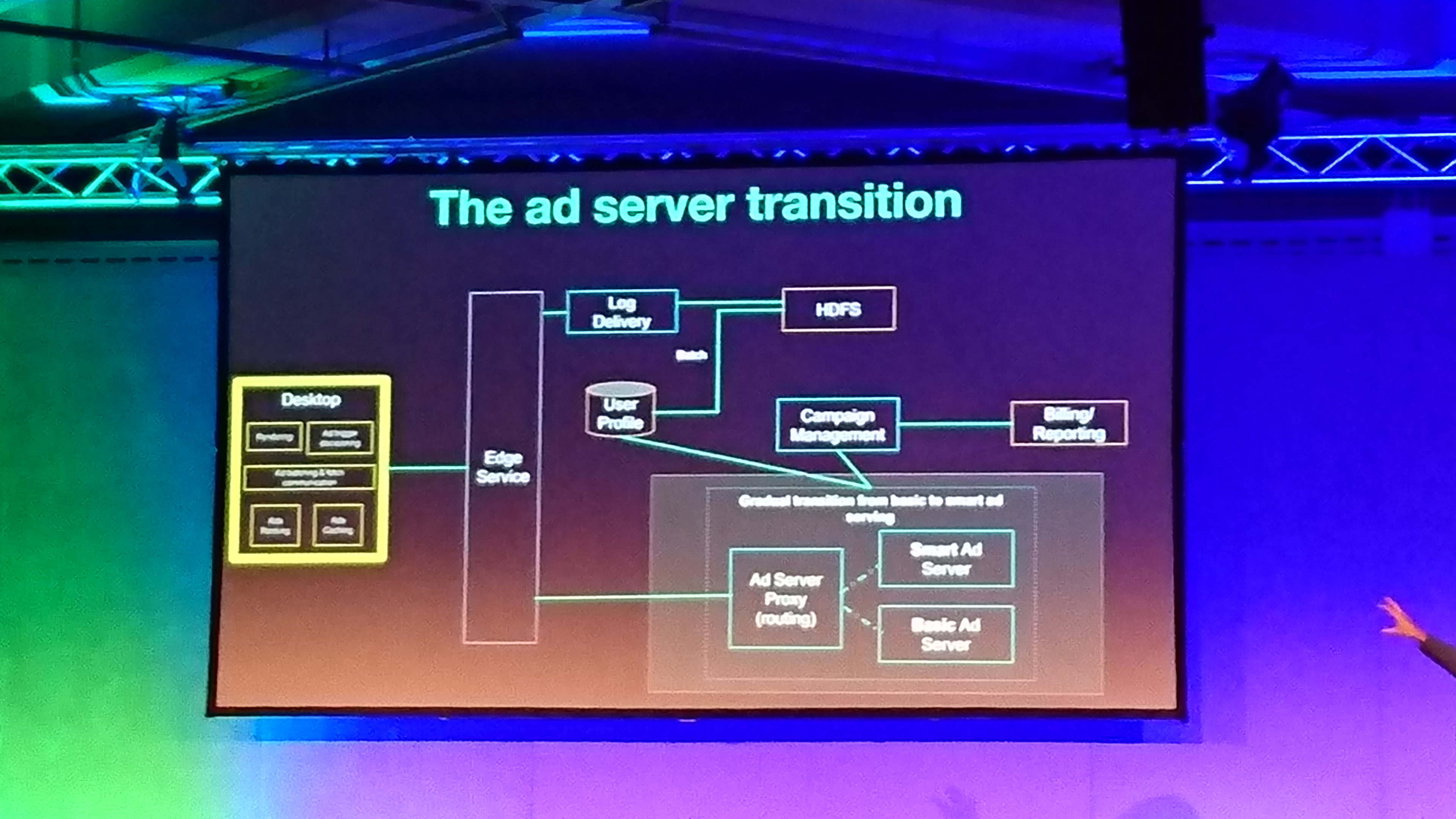
how? keep the existing api so the change is transparent for the client.
took about 18 months.
in the second stage the client was replaced.
it was a big monolyth that was refactored into services.

so the logic was independent and we could change things without breaking completely unrelated things.
Scaling Facebook Live Videos to a Billion Users

1.23 billio access facebook every day.
we have to make sure there people get the best experience possible
facebook live is used to share moments with followers as they are happening.
everything started at a hackaton in april 2015. a hackaton at facebook is an short event where some people come together and do something. people are asked not to do work related things during hackathons.
a few months later afeter the hackathon "mentions" launched in august 2015. in december 2015 "users" launched.
so from 0 to production in 8 months. and everything we launch has to scale to 1 billion users.

there are local pops where users connect, and pops send data between them on big pipes.
facebook live is different from other video platforms, because
- the videos are created in real time and can thus not be cached
- we do not know what video becomes most pupular
we want to go from 0 to production in 4 months and to all users in 8 months.
choosing a protocol for live video: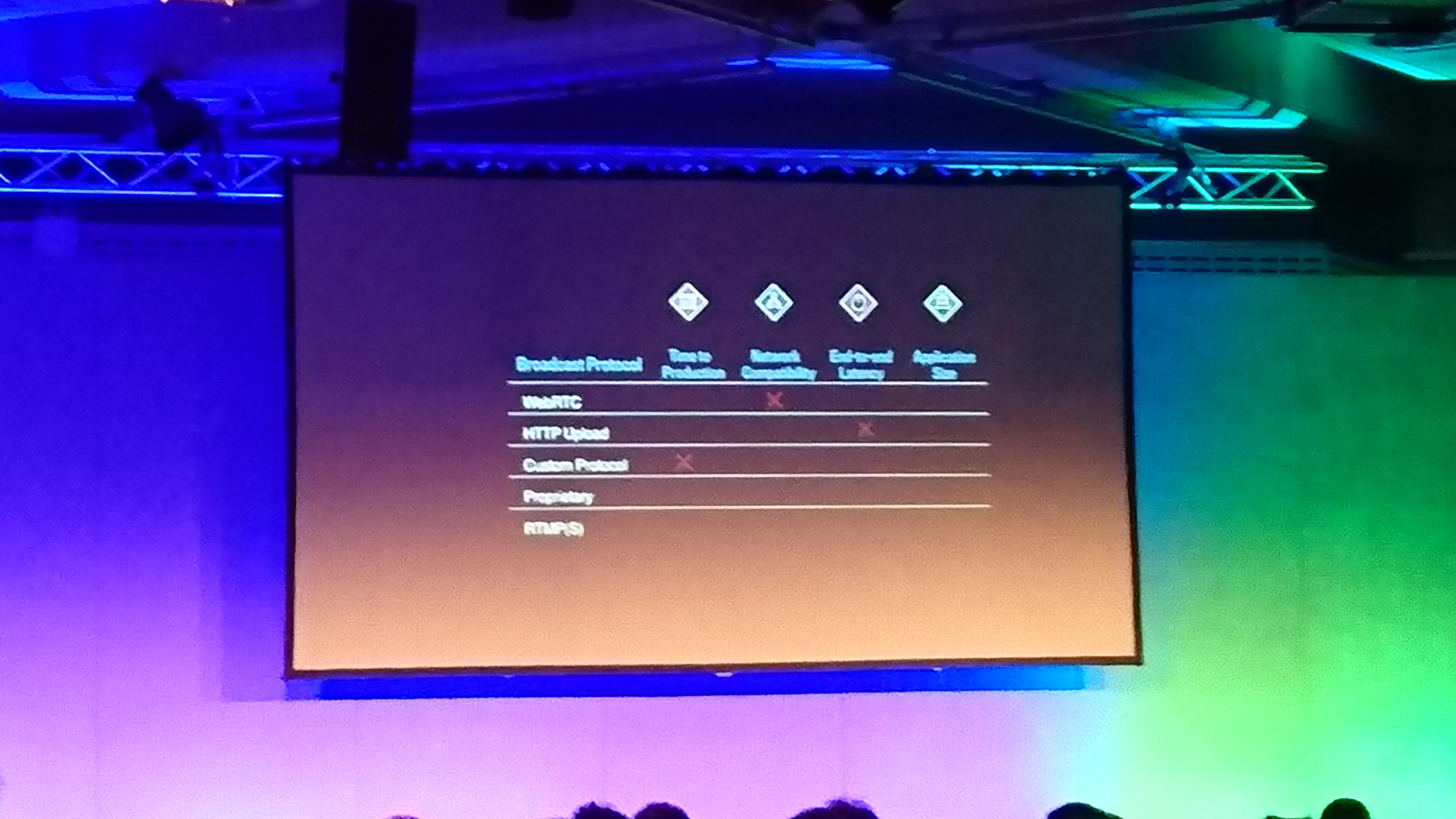
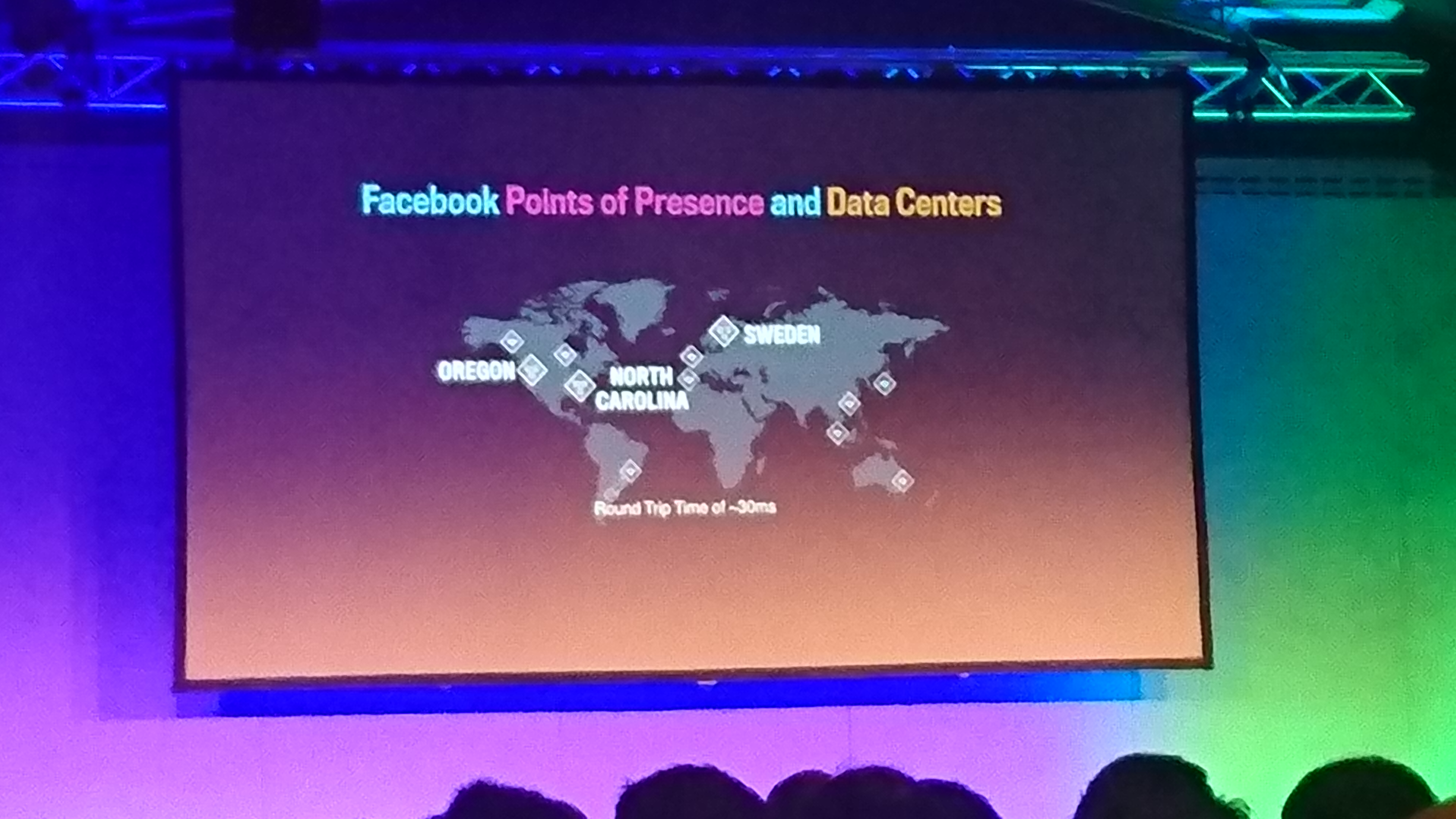
broadcast client -> pop -> datacenter
the pop has scriptable logic: for example it can decide on wich datacenter to store the video based on load balancing logic.
complicated logic with video ids to handle cell phone disconnections and datacenter encoders downtime.
low bandwith has to be handled with adaptive bitrate and buffering on the client.
Shaving My Head Made Me A Better Programmer
A female github employee had the impression she was not beeing taken seriously by her male coworkers, so she shaved her head and saw that people started to ask her technical questions.
Talk about why a diverse environment is important and how to archive it.



cgroupv2: Linux's New Unified Control Group System

why care about cgroups
- 100.000+ servers
- many thausands of services
- wanto ro limit failure domains
need to limit resources to make them available to stuff that needs it


https://www.kernel.org/doc/Documentation/cgroup-v2.txt
use at fb:
Multi-host, Multi-network Persistent Containers
starts with the conclusion :)
apps in containers are stateless, but databases and filesystems sometimes need state.
traditional (broken) development model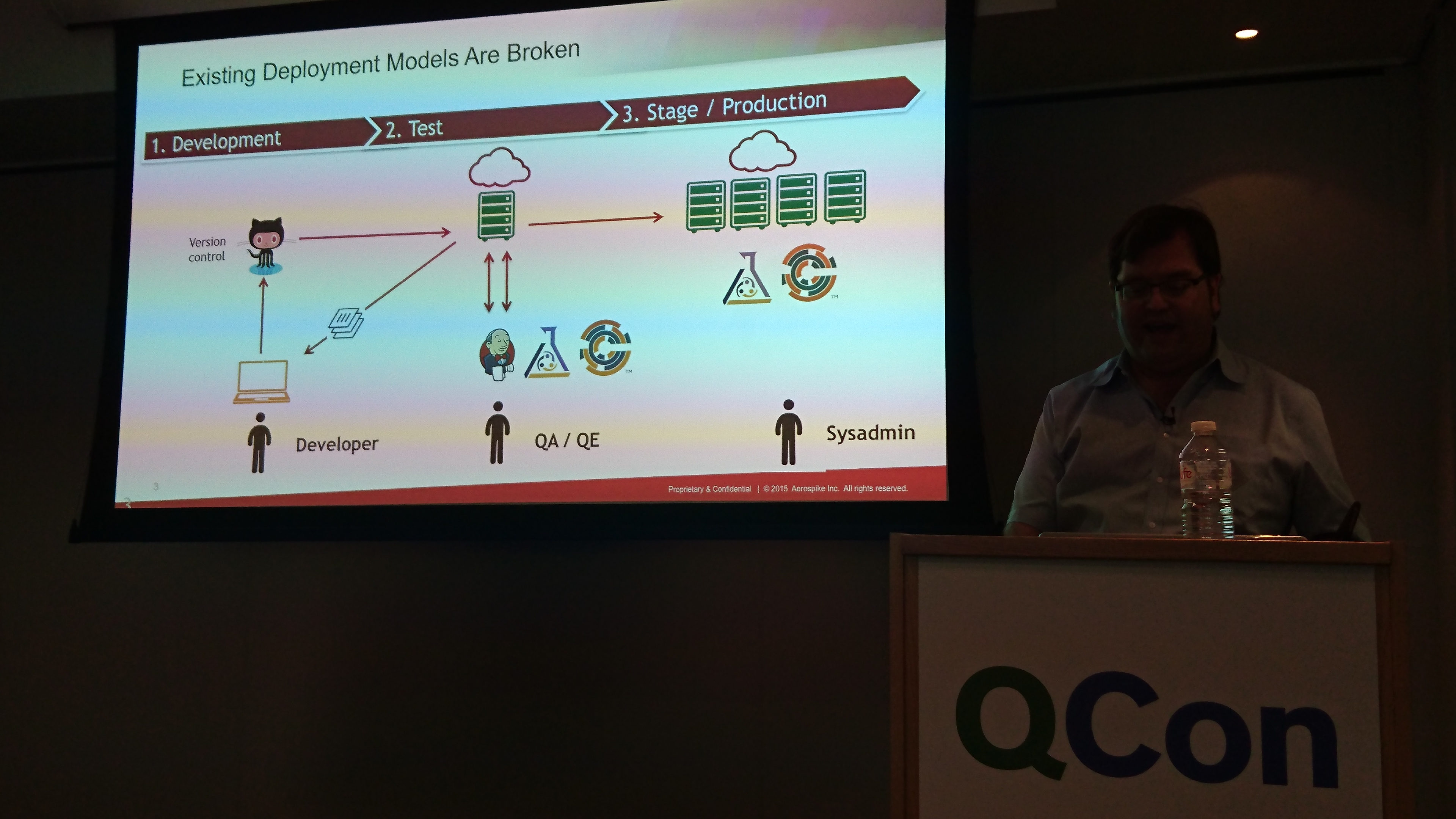
broken because once stuff lands in production it breaks in subtle ways - fixed with containers.
so how do we keep state with containers?
using the cloud is not a great idea, because if you are going to become vendor dependent just buy in on that vendor and use them for everything.

two ways to map persistent storage:
network attached: use a network fs like ciph
local attached: docker has --volumes-from to use containers that contain only storage to use for database containers.
aerospike:
just expose the aerospike with haproxy on the internet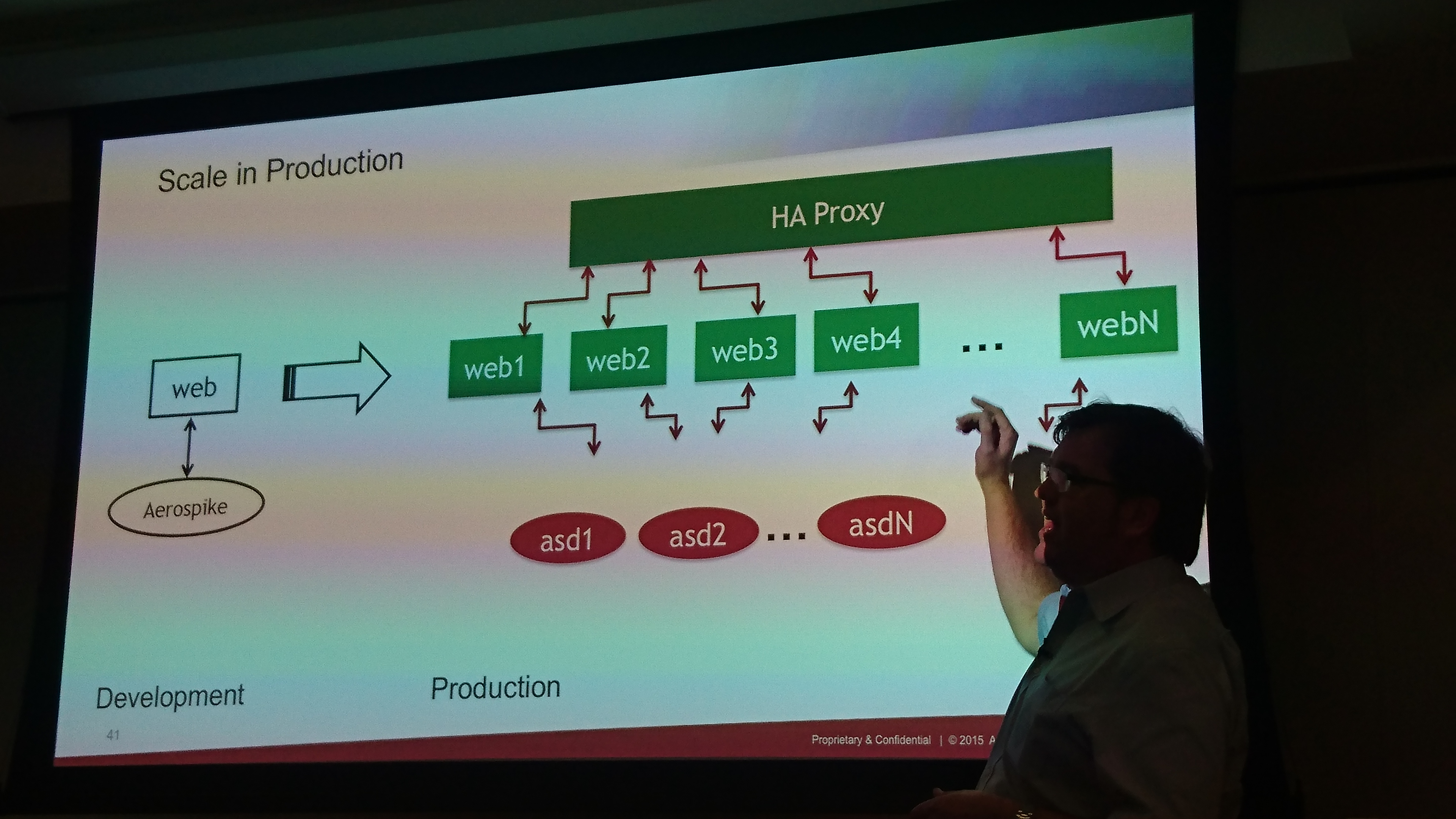
summary
Dev to Prod in 5 minutes: Is Your Company Ready?

the standard git development pipeline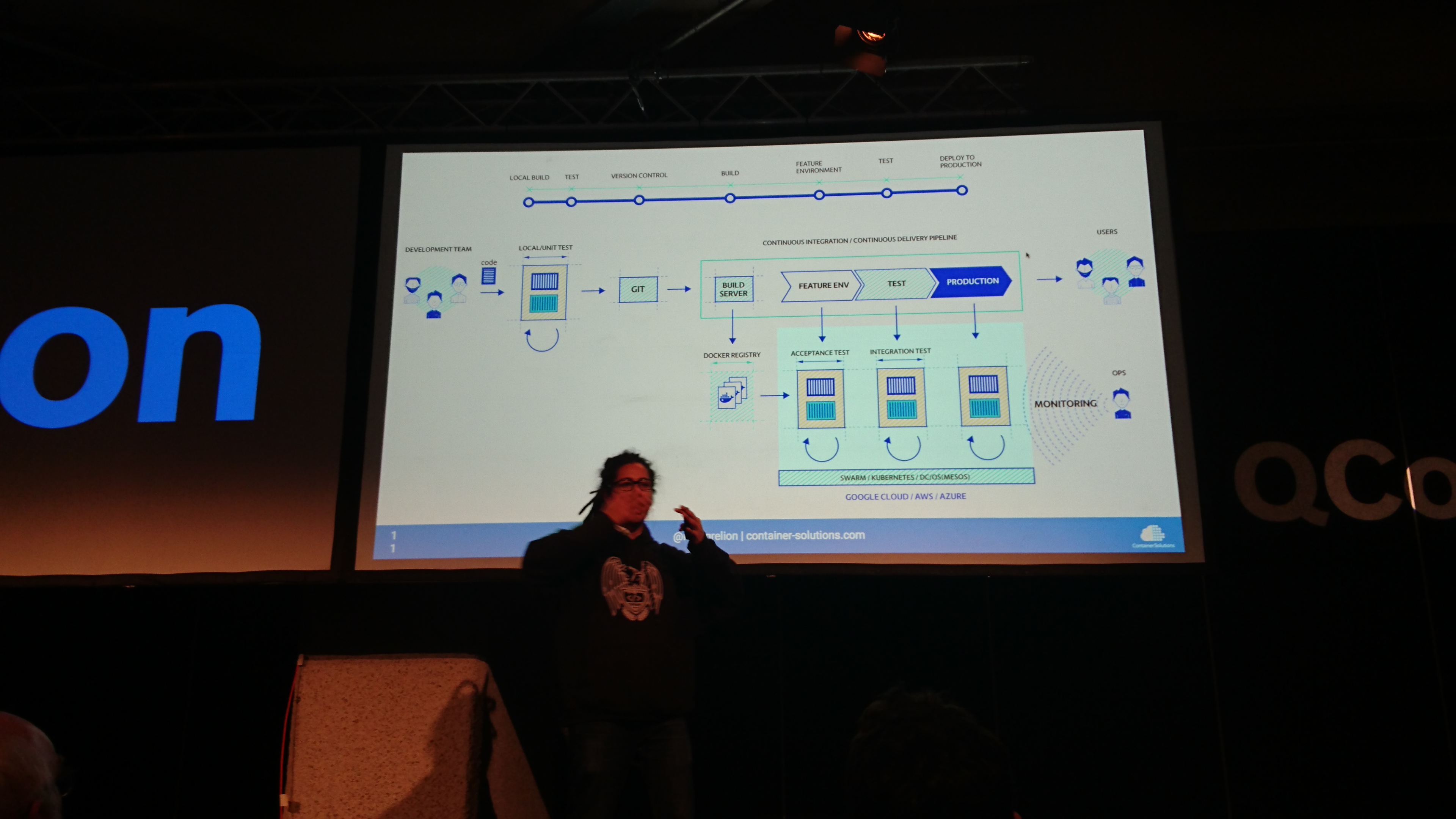
but people don't understand it.
cultural changes are hard. at netflix if you deploy it you own it.
if you try to bring change in the company, think of you as someone who can not do this by yourself, nobody listens to you, you don't have the influence.
- choose allies
- build the right team (take the people that read hacker news, that look at now technologies, that go to conferences, ...)
- choose the right project
- small iterations
- embrace failure (the project may fail, but you will see what went wrong, iterate)
- be ready for inception (people don't like change, but when they see git push and brrrr they will come)
- seek professional help (the idea is that you are going to be the baseline for the company, so if you start with a bad example, people will follow that, because they don't know. so try to make it right.)
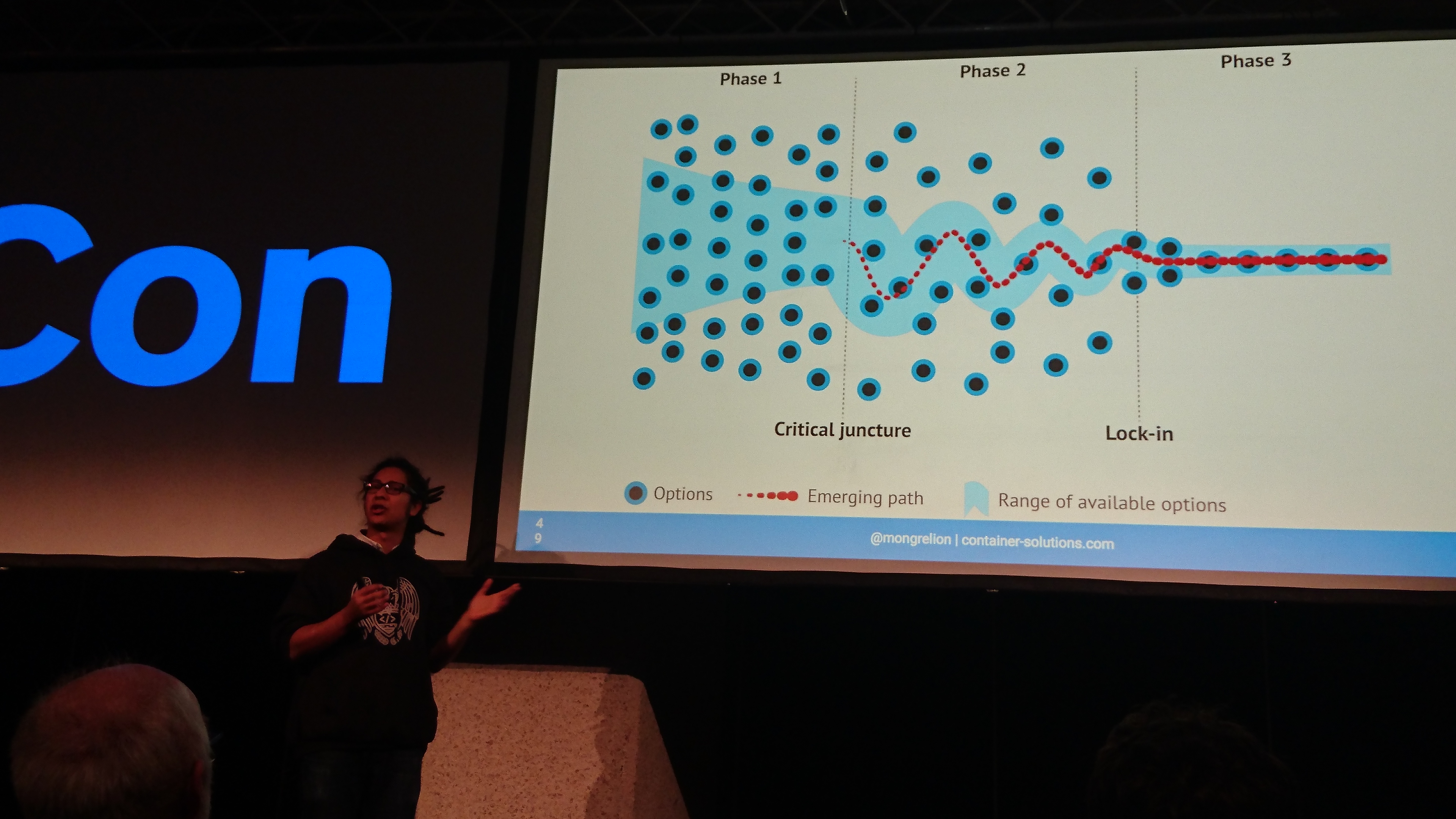
day 3
Our Concurrent Past; Our Distributed Future




Avoiding Alerts Overload From Microservices

knowing when there is a problem is not enough. What you want is get a notification when you need to act. everything else is just noise.

monitoring microservices is very different than monitoring a monolyth. monitoring is harder because you have a lot more services.
- build a system that you can support.
basic tools:
- logging with log aggregation
- monitoring (we use nagios - financial times)
only get an alert when we lose all services in the cluster. if one goes down, who cares as long as the system is up.
we had a very bad idea: make the monitoring screens shift automatically from page 1 -> 2 and it was never on the page we needed.
a click takes you to more detail
to graph stuff we use graphite -> grafana
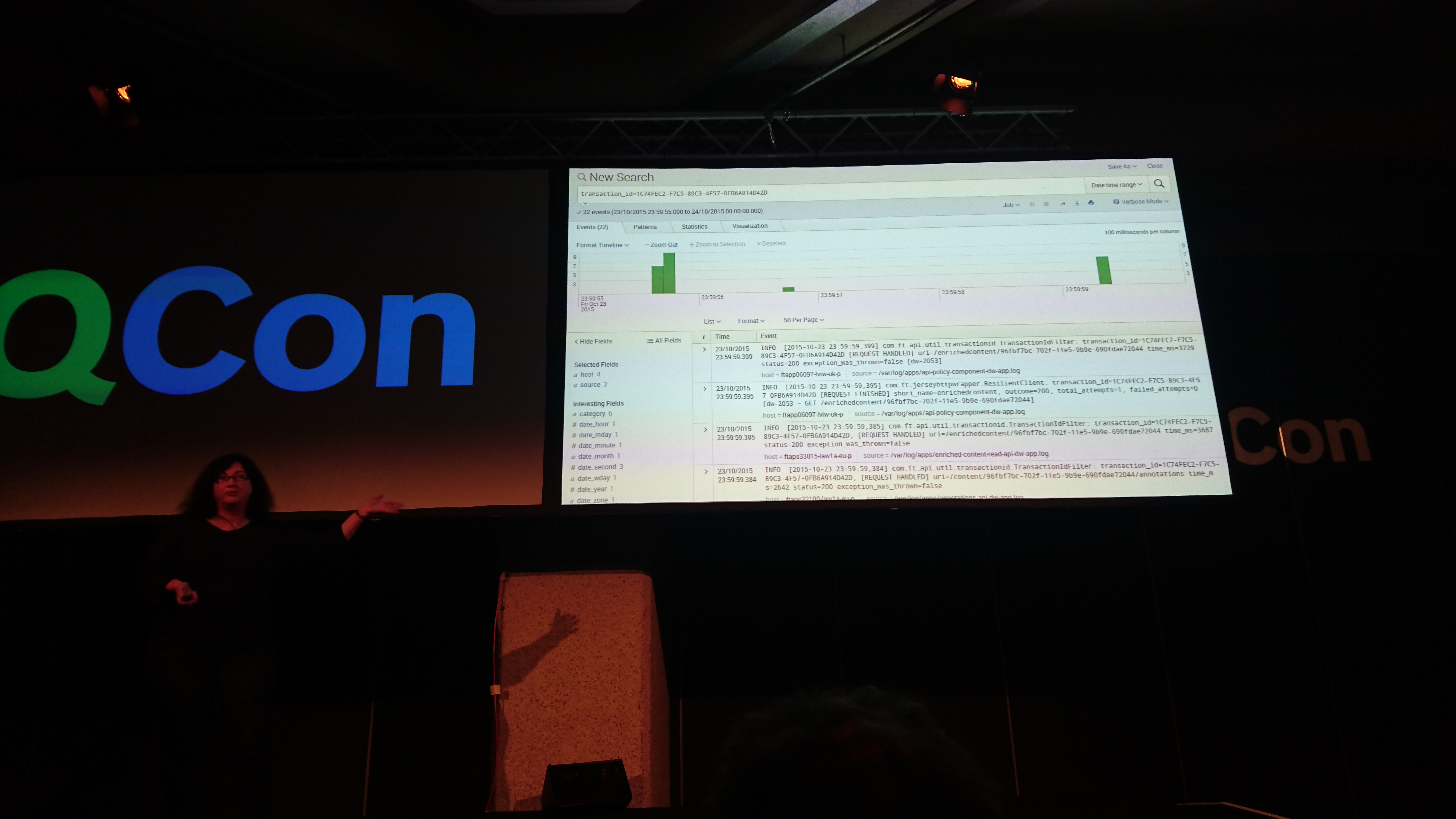
we need to understand how to map the service requests to an http request, so we intoduced transaction_ids. made a java servlet filter so it's easy to integrate. so if you want to debug something, and know the transaction id, you can see all the services involved.
- concentrate on the stuff that matters
if the first attempt failed, but the second got through, i don't really care about the first failure, because basically the thing worked. monitor the business services
- cultivate your alerts
make sure each alert is great!
bad:
good:
make sure alerts can't be missed.
use the right comunication channels.
support isn't just getting the system fixed: we need all to know what happened, how it was fixed, ...

this is important because otherwise people build stuff that breaks.
if you did'nt get an alert, and things did go wrong, something is wrong. you need to fix it. setting up an alert is part of fixing the problem.

you need to make sure that if things break, stuff still works and alerts work. so break things.
- netflix chaos monkey
- ft chaos snail
find ways to share what's changing. we do lot's of showcases.
Do You Really Know Your Response Times?


so how do we measure these things?
sending the metrics from the app is not the solution because it can't measure itself.

dropwizard metrics library.
if something goes wrong, managers want numbers. and these numbers come from these dashboards.

Real World Java 9
lot's of cool new features, one of the biggest one is jigsaw.
case study:
(speaker starts the ide and it takes forever. people laugh.)
the speaker makes a jigsaw module. my impression is that it is a lot of pain: the speaker says there is a lot of trial & error. no automatic creation for the module info file.

speaker says it's not producion ready.
speaker implements (live!) a reactive api.
at the end she says "so now, it does exactly the same thing as before, but with slightly more code."
more demos of java 9 features
- streams api
- collections convenience methods
- additions to interfaces
takeaway points from the speaker: don't jigsaw jour app just jet. it's too early.
Monitoring Serverless Architectures


"sure! what went wrong? can i se the error?"
"we don't know"
"can i see the logs?"
"yeah, but you need to talk to the ops"
and after a few hours you look like this
so why go serverless?
- it's more secure
- it scales up and down
- you don't need infrasructure on your own
- operations: there is a lot of talk about devops, ops, .. in the end it does not matter. you want the services to be up, and serverless gives you that
serverless building blocks
- aws lamda
- aws api gateway
- aws dynamodb
- aws kinesis streams (pub-sub)
- lots more ...

with cloudwatch you can monitor almost anything in all services you use.
- logging
- events

health checks: route53
tracing: aws x-ray
auditing: aws cludtrail
the future: we are in the early stages, but we are headed to total visibility and observability. monitoring is becoming a comodity: it's just one more of the services.


Big Ideas: Decentralized Storage

put data in the cloud without losing control.

save the data on hosts that gain money if they store your data with blockchain smart contracts.
ok it's late.. time to go home.

Simons stuff